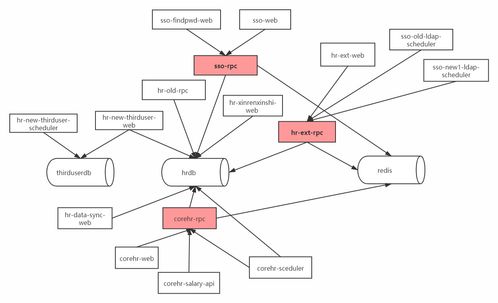
在當今數據驅動的時代,數據庫已從簡單的數據存儲和檢索工具,演變為支撐復雜業務邏輯和個性化體驗的核心引擎。傳統的“一刀切”式數據庫服務模式正逐漸被以用戶為中心、智能化的個性化服務所取代。這種演進不僅提升了數據訪問的效率和安全性,更從根本上重塑了應用與數據的交互方式。
個性化服務的核心內涵
數據庫系統的個性化服務,其核心在于根據不同的用戶角色、應用場景、訪問模式乃至實時上下文,動態地調整其資源分配、查詢優化、安全策略和功能呈現。這超越了簡單的權限管理,是一種深度集成的、智能化的服務體系。例如:
- 資源與性能的個性化:系統能夠識別關鍵業務查詢與后臺分析任務,并為之分配不同的計算與I/O優先級。對于高管駕駛艙的實時報表,數據庫可能提供專屬的內存計算資源,確保亞秒級響應;而對于非緊急的數據挖掘任務,則可以在業務低峰期調度資源。
- 查詢與接口的個性化:不同開發者或數據分析師可能習慣于不同的查詢語言(如SQL、GraphQL)或數據模型(關系型、文檔型)。現代多模型數據庫或云數據庫服務允許用戶通過自己最熟悉的“語言”與數據交互,系統底層自動進行轉換與優化。
- 安全與治理的個性化:基于屬性的訪問控制(ABAC)或動態數據脫敏,可以根據用戶的部門、職務、地理位置甚至訪問設備,實時決定其能看到的數據行、列以及數據的詳細程度。財務總監和一線銷售看到同一張客戶表的視圖將截然不同。
- 運維與調優的個性化:自治數據庫(Self-Driving Database)利用機器學習,持續監控每個特定工作負載的模式,自動進行索引創建與刪除、統計信息更新、參數調優,甚至預測潛在故障并提前規避,實現針對該工作負載的“專屬運維”。
關鍵技術支撐
實現上述個性化服務,離不開一系列關鍵技術的融合:
- 工作負載隔離與管理技術:通過資源池(Resource Pools)、服務等級目標(SLO)保障、以及容器化隔離等技術,確保不同重要性的任務互不干擾,獲得可預測的性能。
- 機器學習與人工智能:AI是驅動個性化的“大腦”。它用于預測查詢模式、自動優化執行計劃、檢測異常訪問行為、以及實現智能的緩存與預取策略。
- 多模型與統一查詢層:底層存儲可能融合了多種數據引擎,但通過統一的查詢接口或智能網關,向上層應用提供個性化的數據視圖和訪問范式。
- 精細化的元數據與策略引擎:系統需要維護豐富的用戶畫像、數據血緣、敏感度標簽等元數據,并與強大的策略引擎結合,才能實時執行復雜的個性化規則。
挑戰與未來展望
盡管前景廣闊,數據庫個性化服務仍面臨挑戰:個性化規則的復雜性可能帶來管理開銷;自動化決策的“黑箱”特性需要可解釋性;在高度個性化的如何保障全局的數據一致性與完整性也是難題。
數據庫的個性化服務將向更深度的情境感知和主動服務發展。數據庫將不僅僅被動響應用戶請求,更能結合業務流程、實時事件和外部數據源,主動推送關鍵洞察或預計算所需結果。它將成為每個應用背后高度定制化、自適應的“智能數據伙伴”,真正讓數據服務無縫融入個性化的數字體驗之中,釋放數據的最大價值。